ParseHub vs Kimono: In a right scrape
Introduction
Recently Hacker Newsletter alerted me to a new visual tool that sounded interesting: ParseHub. This is a powerful (i.e. flexible) yet simple (i.e. graphical) scraping engine that can digest many website structures and produce well-formatted data. In the heterogeneous world of the Internet being able to coerce web pages into homogeneity is something of a holy grail!
Specifically I've long held an ambition to automate the extraction of historical price (and related slowly-varying) data for companies that I might like to invest in. On the face of it this is a simple task but most aggregation sources provide a "snapshot in time" view and individual company websites are frustratingly idiosyncratic. So assembling and cross-referencing this financial data is a time-consuming, manual task.
To test ParseHub (and Kimono; a competitor picked up from Scraping API Evangelist) I pit it against a couple of sites that I favour for solid historical data: Share Prices and InvestorEase. If either tool allows me to download a data history, for a range of companies, in an acceptable format (JSON, XML or CSV) with little more than a few clicks then I count that as a success.
ParseHub
When it comes to defining the shape of your scrape the ParseHub interface is a joy to use. The FireFox add-in provides full control over selecting elements, turning them into lists, linking them semantically and allowing for event-driven navigation. It's a rich tool-set and quite challenging to comprehend - so it's lucky that there are a decent set of tutorials. I worked through all of them to get off the ground.
Once you've got your head around the need to select elements, convert them into lists with a shift-click and then extract the data in order to receive feedback (in a dynamic results pane) then it's relatively straightforward to make progress. Start simple though; I began by trying to navigate between multiple pages, which required simulated user input to display in full, and this was too much. I had to resort to ParseHub support (who were incredibly helpful) to get my over-complicated scrapes functioning.
In use a key strength for this tool is that selections and connections are explicitly visible as an overlay to the source website. This helps you to understand how the page in front of you can be coerced into a hierarchical format. For example this is a snapshot of me capturing two directly related fields, date and price:
However once a scrape project has been defined, and you're keen to convert it into an API, then some of the current rough edges of ParseHub become apparent. The level of documentation around accessing the RESTful API is limited to a single page and there is, as yet, no hand-holding walkthrough available.
That said once I'd realised that there is a distinct three-step, batch-like, process to pulling on-demand data out of a pre-defined scrape then it didn't take me too long to knock up a Powershell script. This is what you need to do:
1 - Kick off the API with your personal API key and a token that uniquely identifies the endpoint. By default this will use whatever parameters the project was created with. To modify these values you can inject a start URL and/or define start values that are referenced in the script.
# Define input values for running scrape
$api_key = "Your personal api key"
$token = "Your project token"
$start_url = "Your URL used to override project start URL"
$fields = @{api_key=$api_key;token=$token;start_url=$start_url}
$uri = "https://www.parsehub.com/api/scrapejob/run"
# Start scrape and retrieve token for run
$return = Invoke-RestMethod -Method Post -Uri $uri -Body $fields
$run_token = $return.run_token
2 - Because you don't know how long an on-demand scrape will take, although you can get a ball-park figure from the time taken to download the underlying page, it's not possible to immediately grab the results. Instead you have to keep polling for the status until the job completes or fails.
# Check status to see if job completed successfully
$run_status = $null
while ($run_status.end_time.length -eq 0)
{
# If the job has no end time then wait before asking again
$run_status = Invoke-RestMethod -Method Get -Uri
"https://www.parsehub.com/api/scrapejob/
run_status?api_key=$api_key&run_token=$run_token"
Start-Sleep -Milliseconds 2000
}
3 - Once the job has completed, hopefully successfully, then go and get the results in JSON (the default) or CSV format (make sure to specify 'raw' else the results will be compressed). This document can be saved directly or easily re-shaped to achieve fine-grained control over your end results.
# Get results if job run successful
if ($run_status.status -eq 'complete')
{
$results = Invoke-RestMethod -Method Post -Uri
"https://www.parsehub.com/api/scrapejob/dl?
raw=1&api_key=$api_key&run_token=$run_token"
# Make results look pretty for output
$results[0].History |
Select-Object -Property 'Type', 'Date' |
Export-Csv -NoTypeInformation "Results.csv"
}
Pros
- Scrape definition is powerful and allows for great control and flexibility in how data is extracted
- The rich tool-set is designed to handle dynamic websites and excels in such use-cases
- Live results of definition can be viewed in real-time as the model is changed
- Can query project APIs on-demand and download results in a timely manner
- APIs are very robust and tend to return results with a delay rather than failing
- Plug-in tutorials are excellent and directly useful - if not essential
- Development team are very responsive and open to questions, feedback and suggestions
Cons
- Steep learning curve with Firefox plug-in means that it's hard to be immediately productive
- Dynamic results pane slows markedly with large datasets (1000s of rows) and has to be disabled
- When you run a project directly on the server the results are compressed, rather than showing in the browser, and this disrupts development flow
- No API to query and retrieve results in a single call which would be useful for lightweight requests
- Queries execute relatively slowly compared to similar scrapers or the underlying page load times
- Scrape results don't appear to be cached and so aren't available if source site is off-line
Kimono
Kimono from Kimono Labs takes a different approach to ParseHub in that it hides the complexity of selecting data relations and navigating around a page structure. All you can do is select a data element, give it a name (optional) and tell Kimono whether its black-box guess of identifying similar elements to group makes sense.
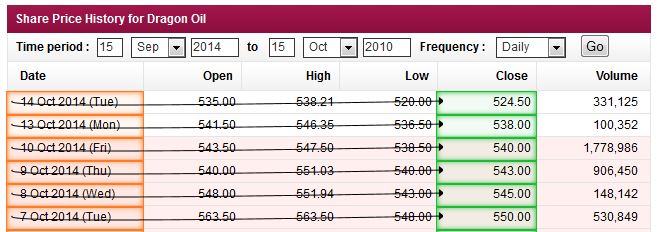
In practice this means that a "tall" column of data is selected and you include/exclude groups in order to focus on a specific table:
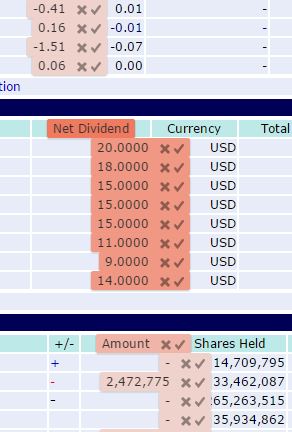
Fortunately the algorithm behind this identification is effective and very intuitive. It took me less than a minute to set up a scrape of dividend history data and that's without going near a tutorial. Wow! With a selection of interesting table fields I easily checked the data collection structure, intuited by Kimono, on the next tab:
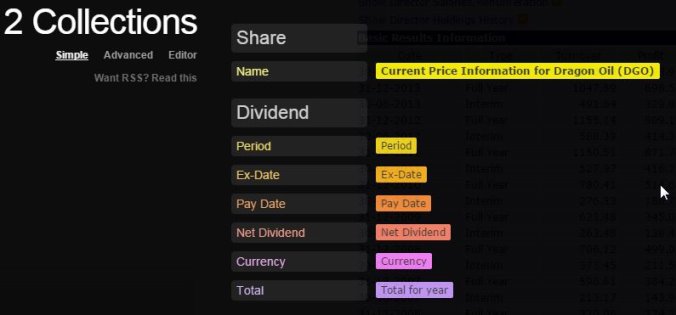
With a sensible structure in place live data can be directly downloaded in a variety of formats (JSON, XML, CSV etc.). However it's much more fun to set up an API that can be re-used and shared. When you do this Kimono is smart enough to detect query string parameters relevant to the source page and add them to its API definition - which transforms any API into a general-purpose scraping tool.
In order to get your hands on some scrape results the Kimono preference is that you should schedule runs ahead of time and pick up historical results from their servers. This allows them to spread the load and implement caching. As a consequence there are explicit (a throttle of one call every 5 seconds) and implicit (in testing I seemed to max-out my ability to make further calls) limitations to on-demand runs.
That said the live API is very easy to use and typically requires but a single call:
# Get results from API in single call
$results = Invoke-RestMethod -Method Get -Uri
"https://www.kimonolabs.com/api/YourApi?
apikey=YourKey&epic=$ticker"
# Make results look pretty for output
$results[0].results.History |
Select-Object -Property 'Type', 'Date' |
Export-Csv -NoTypeInformation "Results.csv"
The only real complication arises when your scrape returns in excess of 2500 rows. Kimono restricts all datasets to this size. To work around this you end up paging through the results in groups and aggregating them. In my testing here the data set tops out at about 4500 rows and so two calls is sufficient:
# Get the first ten years of data (2500 record limit)
$results = Invoke-RestMethod -Method Get -Uri
"https://www.kimonolabs.com/api/YourApi?
apikey=YourKey&tidm=$ticker"
# Output first chunk of data
$results.results.Prices |
Select-Object -Property 'Date', 'Price' |
Export-Csv -NoTypeInformation "Results.csv"
# Get the next ten years of data
$results = $null
$results = Invoke-RestMethod -Method Get -Uri
"https://www.kimonolabs.com/api/YourApi?
apikey=YourKey&kimoffset=2500&tidm=$ticker"
# Append the next chunk of data
$results.results.Prices |
Select-Object -Property 'Date', 'Price' |
Export-Csv -NoTypeInformation -Append
"Results.csv"
Pros
- Extremely simple to use the Chrome plug-in and throw together a model
- Definition results can be viewed and downloaded in real-time as model is changed
- Can query project APIs on-demand and download results in a timely manner
- There's a lot of static and interactive documentation to support users
- Scrape results are obtained and returned extremely rapidly (independent of any caching that may be occurring)
Cons
- It's not clear how well Kimono scales to more complex models as pagination seems to be the most powerful feature on offer
- When aggregating large result sets there is a tendency for the server to return a 503 error and this leads to corruption when aggregating
- When an API scrapes no data it silently returns the results of the previous call rather than return nothing (false positive)
- Limits around on-demand calls restricts how quickly or broadly you can interrogate apis
- Scrape in browser slows down when parsing several thousand records although still remains responsive
Conclusion
In terms of the actual data being downloaded, and the ease with which I can manipulate it, there's nothing to choose between the two tools. Both are perfectly able to parse the selected websites and generate effective models. With more dynamic scenarios ParseHub will likely win through sheer flexibility but I haven't reached that point yet.
On the usability front Kimono offers a decent balance between ease of use and power. You can dive right into a web page, isolate exactly the fields of interest and quickly decide whether it's feasible to pull out that data that you want. There's little friction to impede progress for beginners or anyone with a one-off, ad-hoc requirement.
But usability isn't the only criteria. If a web scraper can't reliably deliver accurate, consistent results every time then you'll waste much more of your life sanitising your data than you ever did in setting up the initial project.
So my final test is to attempt a bulk, sequential download. With a few Powershell scripts it's a doddle to do; even for 75 companies. A fairly taxing task for the servers though as just opening the underlying pages for each company takes around 30 seconds. In this case though I just want the data to be right and I don't care how long this takes.
For Kimono the bulk scrape takes about 85 minutes and returns most of the data requested. However 20 of the heaviest queries (requiring paging) fail with a (503) Server Unavailable error. In addition requests that should return no data instead pass the same data as delivered immediately before. This isn't a fire and forget solution.
With ParseHub the scripts take about 50% longer to run overall. Individual scrape timings are broadly similar but occasional calls block for just over 300 seconds before returning successfully. No connections to the servers fail though and when my inputs are good I receive all of the data expected (and no data when the inputs are bad).
Ultimately I like using both tools; Kimono for its usability and ParseHub for its power. Both have their place but to be confident that I'm downloading the data I want, and just the data I want, then the choice has to be ParseHub. There's nothing worse than second-guessing your data and now I don't have to.